
Skeletal data, as used in machine learning, is the abbreviated depiction of the human body as a set of points, usually representing bones and joints. This kind of data, which is frequently obtained via depth sensors or motion capture systems, is becoming a crucial tool for activities like sign language translation and human action recognition (HAR). We will examine the benefits of using skeleton data in machine learning as well as the models that make use of it in this blog.
What is Skeleton Data?
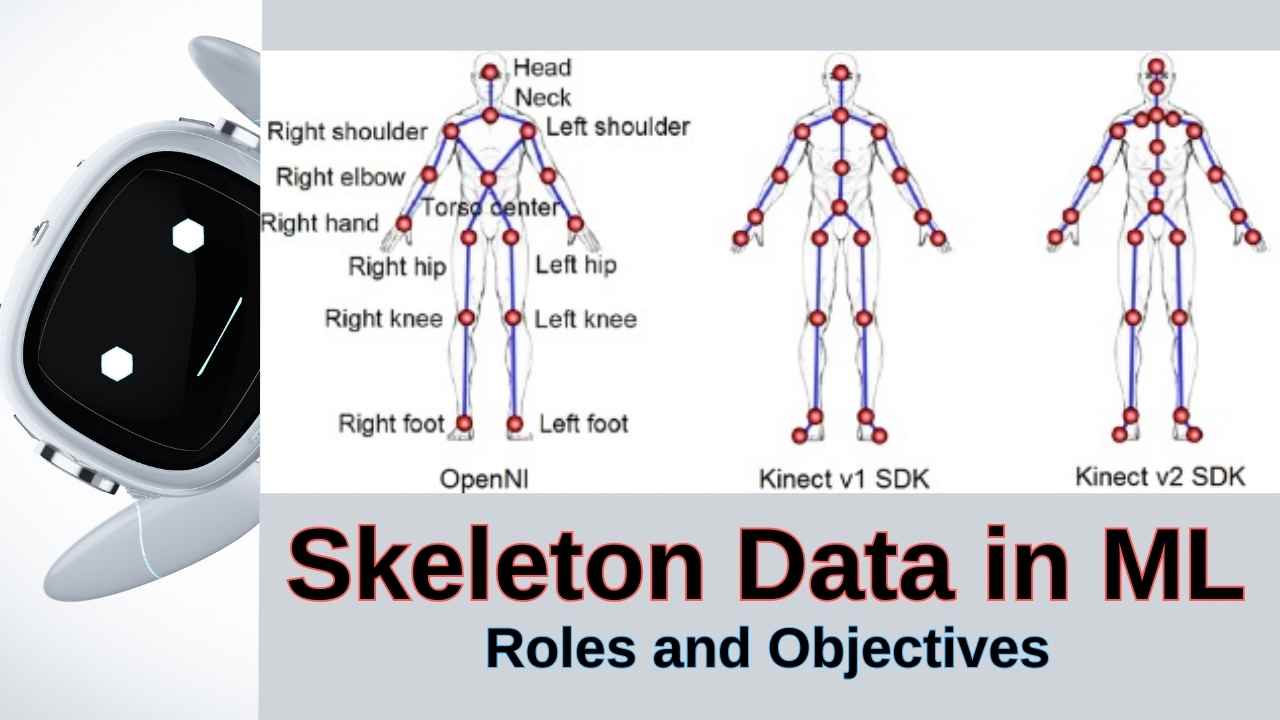
A graph-like structure made up of nodes (joints) and edges (bones) is how the human body is represented by skeleton data. By concentrating on the main body parts associated with movement, this simplified representation simplifies the raw video data and frees up machine learning models to focus on the underlying motion patterns.
For instance, in a skeleton representation, a directed acyclic graph (DAG) is formed by the edges (bones) connecting joints like the shoulders, elbows, knees, and hips. Because it represents the body’s spatial arrangement, this representation is an effective input modality for a range of motion analysis applications, including gesture-based interfaces and action detection.
Applications of Skeleton Data
Human Action Recognition (HAR): HAR is one of the main applications for skeletal data. The analysis of joint locations can be used to define more complicated activities like dancing or martial arts, as well as simpler movements like walking, running, and jumping. Deep learning-based architectures, in particular, are very good at learning the temporal and spatial dynamics of these movements using machine learning models.
Human Pose Estimation: The foundation of human pose estimation models is also skeleton data. By detecting major body joints, these models are able to determine the location and orientation of an individual within an image or video frame. This method is applied in fitness tracking, medical rehabilitation, and gaming (e.g., Kinect systems).
Skeletal data is used in sign language recognition to follow hand and body motions and convert gestures into meaningful discourse. Machine learning models can comprehend complicated hand movements involving joints such as the wrist, elbow, and fingers, which can help improve the accuracy of sign language translation.
Why Use Skeleton Data
Skeleton data offers several advantages over raw video or image data:
Dimensionality Reduction: Compared to RGB video data, skeleton data is far more efficient and requires a smaller input size. Models concentrate just on important locations rather than analyzing every pixel, which speeds up and reduces the computational burden of training.
Invariant to Appearance: Skeletal data is relatively invariant to appearance, in contrast to video data, which can be impacted by backdrop clutter, lighting, or clothes. This aids models in concentrating on the essential movement patterns rather than unimportant details.
Captures Kinematics: The interactions between joints and bones are intrinsically encoded in skeleton data, making it valuable for organizing the analysis of movement patterns. For understanding intricate, long-term interdependence in motion sequences, this makes it perfect.
Machine Learning Models
Several machine learning models have been tailored to process skeleton data effectively:
Convolutional Neural Networks (CNNs): By treating joint positions as spatial characteristics, CNNs can be used to analyze skeletal data. This is furthered by Temporal Convolutional Networks (TCNs), which are essential for action recognition tasks because they can capture temporal relationships in the movement.
Recurrent Neural Networks (RNNs): RNNs, like LSTMs and GRUs, are frequently used to describe the temporal dynamics of skeletal data because it consists of sequences of movements across time. They work especially well for recording long-range dependencies, including intricate action sequences.
GNNs, or graph neural networks: Graph-based models such as Graph Neural Networks are well suited to analyze skeleton data, which is organized as a graph of joints and bones. GNNs facilitate improved action detection and pose estimation by efficiently capturing the connections between various joints.
Transformers: Processing skeletal data has made transformers more and more popular recently. Attention mechanisms are used by models like the Vision Transformer (ViT) and Multi-Scale Transformer to capture temporal and spatial correlations in skeleton data. Large datasets may be processed by these models, and they excel at difficult tasks like identifying intricate human relationships or behaviors.
Challenges and Future Directions
Even though skeleton-based machine learning models have made great strides, there are still issues. It is still challenging to reliably capture fine motor motions, such as fingers in sign language, and deal with occlusions or noisy data. Furthermore, in many applications, the requirement for sizable labeled datasets for training still poses a challenge.
Even though skeleton-based machine learning models have made great strides, there are still issues. It is still challenging to reliably capture fine motor motions, such as fingers in sign language, and deal with occlusions or noisy data. Furthermore, in many applications, the requirement for sizable labeled datasets for training still poses a challenge.
For applications such as action identification, pose estimation, and gesture recognition, skeleton data is essential for streamlining and optimizing machine learning models. Skeletons-based models are effective, reliable, and strong because they simplify the raw video data and concentrate on important motion-related aspects. Applications and techniques for using skeleton data will advance along with machine learning, opening up new possibilities in computer vision, human-computer interaction, and other domains.


{kind=link}